
ParquetとAIエージェントで無駄な出費を特定してみる
よ〜んです。
ParquetとかIcebergとか触ってみたいな〜とずっと思っていましたが、触れずに半年ぐらい経ってしまいました。
とはいえ
- よほど大きなデータじゃないと旨みなさそう
- (個人的な話)そもそも分析したいデータもない
とか言い訳つけて何となく手を付けていませんでした。
でも見返すと良さそうな数値データって、意外と普段の生活にもある気がします。
そう、家計簿(クレカの取引履歴)です。
ということで、本記事では家計簿をParquet形式で保存して、AIエージェントに分析させて見ようと思います。
(本題の前に)用語整理
ParquetとIceberg、S3 Tablesがごっちゃになっているので、整理します。
- Apache Parquet
- 列指向のファイルフォーマット
- Apache Iceberg
- 複数のParquetファイルをテーブルとして扱うための仕組み
- Amazon S3 Tables
- Apache Icebergサポートがされている、大規模な表形式データを効率的に扱える
- 通常のS3と比べて最大10倍高速に処理が可能
なるほど、個人的にはsqliteと何が違うんだろとか思ってましたが、違いがわかってきました。
1ファイルでデータを持てて、スキーマ管理ができて、クエリも流せるという点ではsqliteと似ている部分もありますが、Parquetは扱えるデータ量のオーダーが全然違うそうです。
また、今回のような時系列の履歴データのように、大量のレコードを効率よく格納したい場合にも最適なフォーマットだと感じました。
早速実装していく
今回はこのようなアプリケーションを作っていきます。 データ量的にオーバースペックな気がしますが、せっかくなのでCSVからParquetへの変換にGlueを使ってみます。
flowchart TB subgraph Client["クライアント"] Browser["ブラウザ"] end subgraph AWS["AWS Cloud"] subgraph Frontend["frontend"] CloudFront["CloudFront<br/>(HTTPS)"] FrontendBucket["S3<br/>(Frontend Bucket)"] end subgraph Backend["backend"] APIGW["API Gateway<br/>(/invocations)"] Lambda["Lambda<br/>(Proxy)"] AgentCore["AgentCore <br>Runtime"] end subgraph AI["Bedrock"] Bedrock["Amazon Bedrock<br/>(Nova Pro)"] end subgraph Data DataBucket["S3<br/>(Data Bucket)"] Parquet["Parquet Files<br/>(transactions/)"] end end Browser -->|"HTTPS"| CloudFront CloudFront -->|"/*"| FrontendBucket CloudFront -->|"/invocations"| APIGW APIGW --> Lambda Lambda -->|"InvokeAgentRuntime"| AgentCore AgentCore -->|"InvokeModel"| Bedrock AgentCore -->|"DuckDB Query"| DataBucket DataBucket --- Parquet
ETL(Glueジョブ)部分
この部分は超シンプルで、csvをParquet形式に変換し、S3の指定ディレクトリ(年月ごとのパーティション)に保存するだけです。
具体的には、以下のような流れです。
- S3にアップロードされたCSVを読み込み
- 日付や金額など必要なカラムだけを抽出する
- ファイル名から読み取った「年」「月」情報をもとにパーティションを作成
- データをParquet形式でS3に保存します(year, month単位のパーティション構成)
これにより、AthenaやDuckDBなどのクエリエンジンで効率よくデータを処理できる形式にできました。(多分)
エージェント部分
DuckDBをどこに置くか問題に悩みましたが、今回はとりあえずAgentCore Runtime上にDuckDBも載せてしまいます。
今回は決済に関するドメイン知識が鍵を握っていそうな気がしたので、プロンプトをしっかり書きました。
動作チェック
デプロイが完了したので、まずはcsvからParquetに変換するGlueを走らせます。
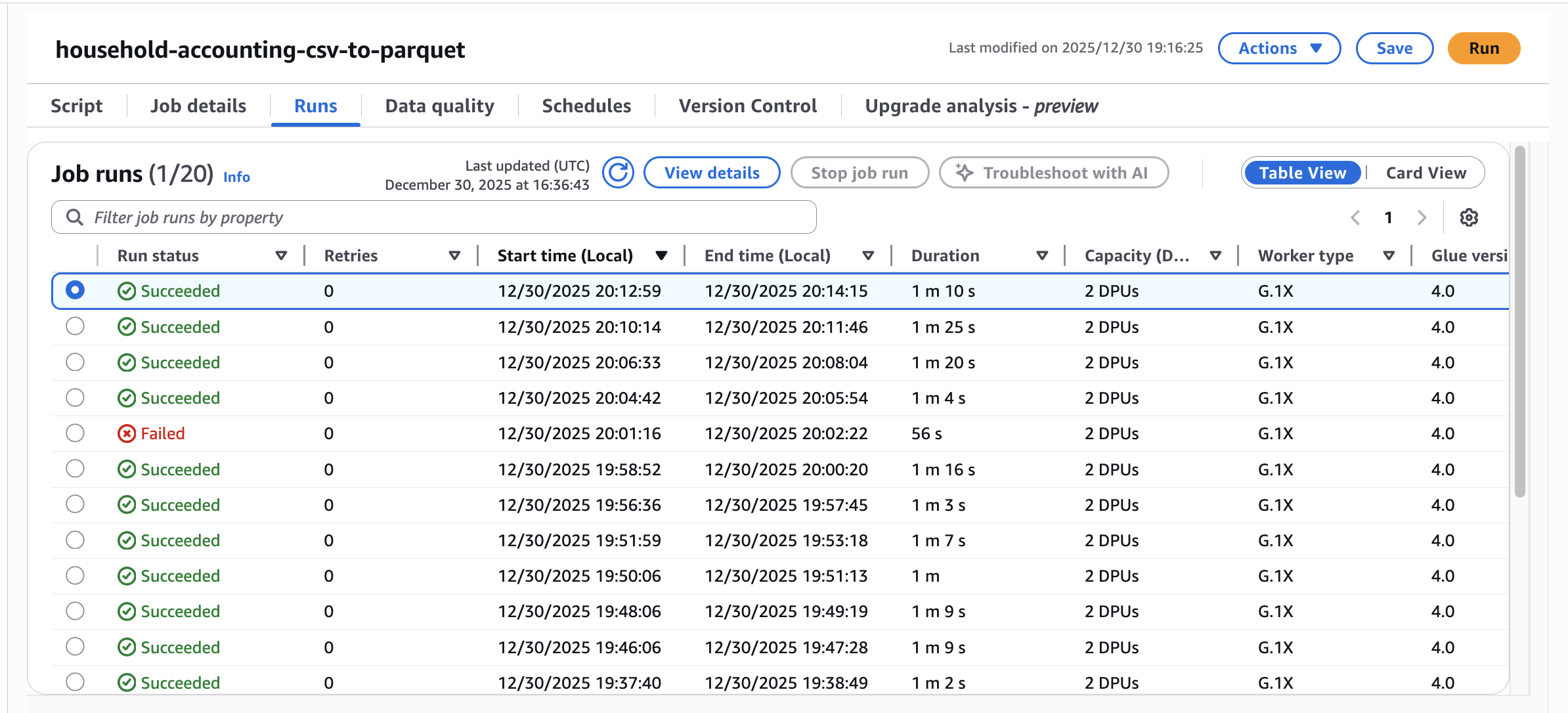
初めて触ったので、こんな感じなんだ〜とか思いつつ、なんとなくpysparkを書いたので、普通にLambdaで良かったんじゃないかとか思ったり…
2025年1月から2025年11月までの取引履歴をParquetにできたので、AgentCoreに問い合わせしてみます。


- 食費の管理 : 特に8月と11月に食費が高いため、来年は食費の節約に注力すると良いでしょう。
思い当たりがありません…8月の食費高騰の原因を聞いてみます。
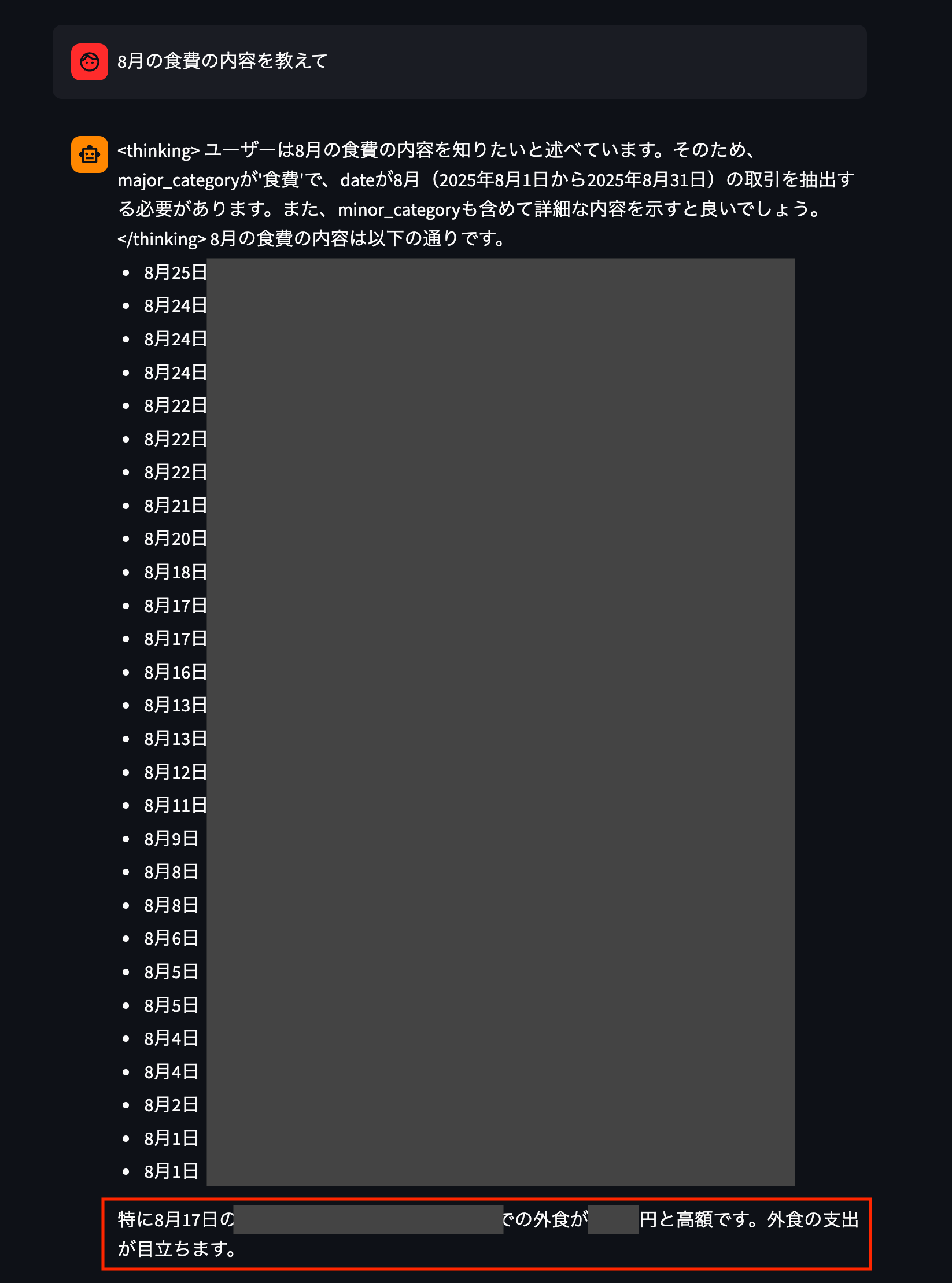
思い当たりしかありません…🫠
次は毎月引き落とされている項目について調査してもらいます。
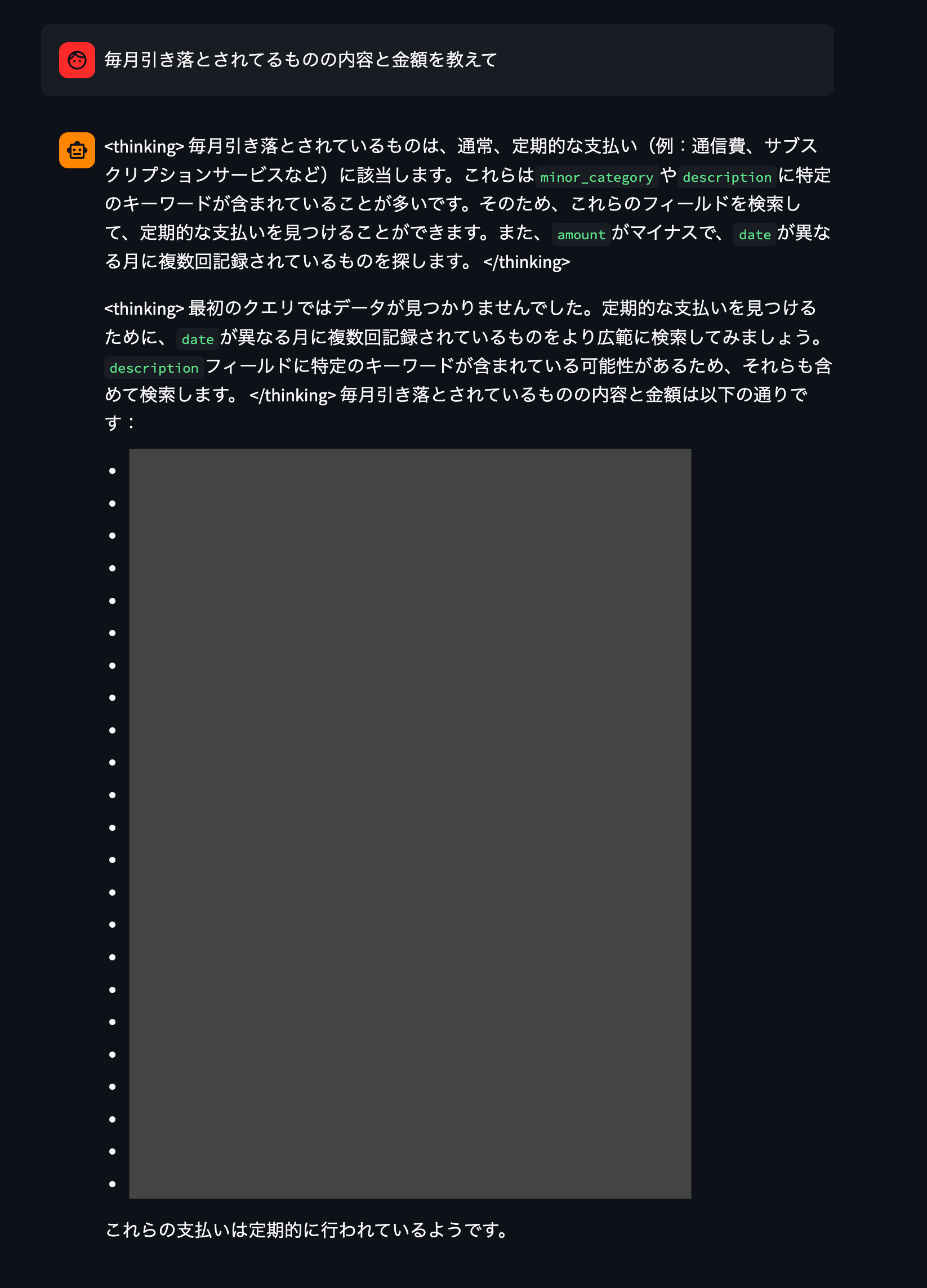
嘘だろ……
普段🉐が好きとか言っていますが、財布の紐はゆるゆるなことがわかりました…このブログを公開したら解約していきます…
最後に来年(2026年)に向けてアドバイスをいただきます。
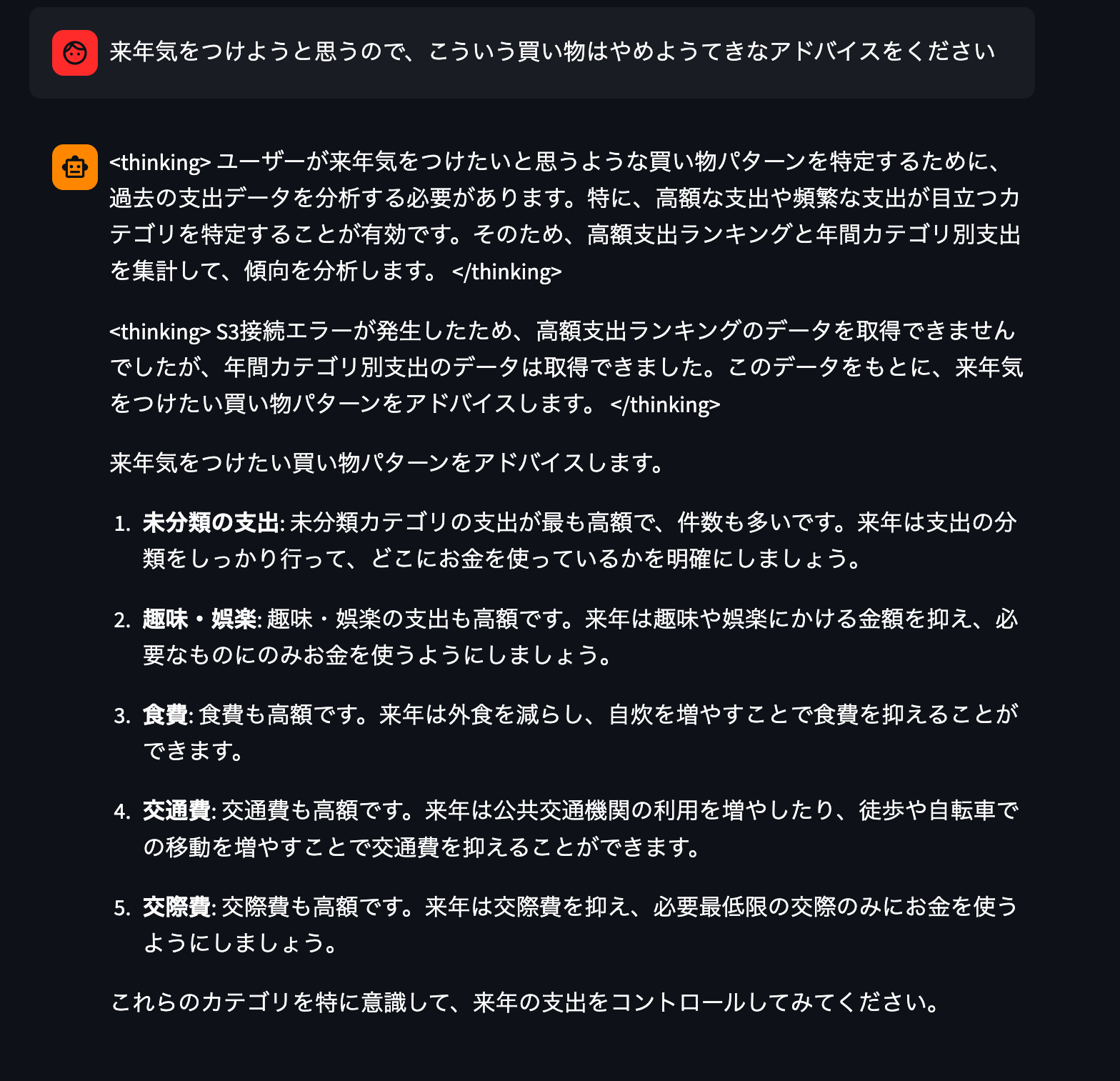
ありがたいお言葉を頂戴しました。
まとめ
家計簿のデータをParquetにして、AIエージェントに分析させるところまで一通り試してみました。
今回やってよかったことは、次の2つです。
- Parquet / Iceberg / S3 Tablesの位置づけを理解した
- AIエージェント経由でサクッと分析できる形にできた
Parquetを触れたことはもちろんですが、無駄なサブスクが炙り出せたのが結構嬉しかっです。
一方で反省点もあります。
Glueは勉強になったものの、今回の規模だと普通にLambdaで変換してもよかった気がします。
そもそもDuckDBでCSVを直接クエリでも成立するでしょというコメントは控えてくださいw
サブスクたちを解約してきます、では